Versioning Knowledge for RAG: How to Reindex, Roll Back, and Audit Retrieval Changes Safely
A team I worked with once treated their retrieval layer like a cache: useful, replaceable, and not particularly deserving of release discipline. Their product was a customer support copilot backed by a few million internal documents, policy pages, runbooks, PDFs, and ticket summaries. The application team had CI/CD. Prompt changes had review. Model changes had canaries. But the knowledge layer—the corpus preprocessing, chunking logic, metadata schema, embeddings, and indexes—was managed with a mixture of scripts, ad hoc notebooks, and best intentions.
Then they changed chunking.
The old pipeline split documents by fixed token windows with modest overlap. The new one attempted semantic sectioning, preserved tables better, and introduced richer metadata for business unit, policy effective date, geography, and access tier. It looked like a clear improvement. Early spot checks looked good. The team kicked off a rebuild over the weekend and cut over on Monday.
By Tuesday, the support organization reported that answers were “more confident but less reliable.” A compliance lead noticed that some responses cited superseded policy documents because the new metadata schema had not been backfilled consistently. Search relevance looked better on long technical articles but worse on procedural docs where users needed the exact latest step sequence. Latency increased because the retriever now fanned out across more chunks per query and reranking load spiked. Worse, when the team tried to roll back, they discovered they had overwritten the old index aliases and could not reconstruct exactly which corpus snapshot, chunking config, and embedding model had produced the prior behavior.
Nothing was catastrophically broken in the traditional sense. The app stayed up. The model answered. Dashboards showed requests completing. But the product had suffered a silent retrieval regression, and the team had no clean rollback, no durable audit trail, and no principled way to compare the old and new retrieval behaviors.
That story is common because many teams have learned to treat prompts and models as versioned assets, but they still treat “the knowledge base” as a blurry substrate underneath the application. In production RAG, that substrate is not a passive store. It is a deployable artifact with behavior, failure modes, and compliance consequences.
If you operate RAG in production, you should version the knowledge layer with the same seriousness you apply to application code and model serving. That means not just versioning documents, but versioning the full retrieval contract: document snapshot, canonicalization rules, chunking strategy, metadata schema, embedding model, index build parameters, filtering behavior, reranking stack, and release criteria. It also means having a deployment pattern for rebuilding indexes without downtime, diffing retrieval changes before cutover, and rolling back safely when quality or policy issues emerge.
This article lays out a production pattern for doing that.
The pattern: treat retrieval as a releaseable artifact
The central shift is conceptual: stop thinking of your vector store or hybrid search layer as a mutable database that gradually “contains knowledge,” and start thinking of it as a built artifact produced by a deterministic pipeline.
A retrieval build should be reproducible from explicit inputs:
- A corpus snapshot
- A document normalization pipeline version
- A chunking strategy version
- A metadata schema version
- An embedding model version
- Index engine and parameter settings
- Reranking model/version, if applicable
- Access-control and filtering rules
- Build-time validation results
- Evaluation results and release approval
That collection should produce a named retrieval release, similar to a container image or model artifact. For example:
kb_release=2026-06-15_policy_v4corpus_snapshot=s3://kb-snapshots/2026-06-14T23:00Zchunker=semantic_sections@2.3.1metadata_schema=policy_meta@4embed_model=text-embed-large@2026-05vector_index=hnsw(m=32,ef_construction=400)reranker=mini-cross-encoder@1.8
That sounds bureaucratic until you need to answer one of these production questions:
- Why did answer quality drop after Tuesday’s release?
- Which users were exposed to outdated policy citations?
- Did the new index accidentally include restricted documents?
- Can we reproduce the retrieval state from last month for an audit?
- How much of the observed change came from chunking vs embeddings vs reranking?
- Can we revert only retrieval without reverting the entire application?
If the answer to those questions depends on tribal memory or best-effort reconstruction, the retrieval layer is under-managed.
Why the naive approach fails
Most RAG systems start with a simple mental model:
- Ingest documents.
- Chunk them.
- Compute embeddings.
- Upsert into a vector DB.
- Query by similarity.
That is enough for prototypes. It is not enough for production, because nearly every step changes system behavior in ways that are hard to see until users feel them.
1. “Just reindex in place” destroys rollback
Many teams update the existing index in place. They change chunking rules or metadata fields, recompute embeddings, and overwrite existing entries. It feels operationally simple because there is only one live index.
The downside is severe:
- You lose the previous retrieval state.
- Mixed old/new chunk populations create inconsistent behavior during rebuild.
- Query metrics become hard to interpret because the index contents change continuously.
- If the new build is flawed, rollback may require a full rebuild rather than an alias switch.
- Auditability collapses because there is no durable mapping from a production answer back to the exact retrieval artifact used.
In-place mutation is acceptable for tiny systems where retrieval is non-critical. It is a liability anywhere retrieval quality affects trust, workflow efficiency, or policy compliance.
2. Document versioning alone is insufficient
Some teams say, correctly, that their source content is versioned in Git, SharePoint, Confluence, or a document management system. But the retrieval behavior is not determined by the source documents alone.
The same corpus can produce dramatically different results depending on:
- Parsing and OCR quality
- Boilerplate stripping
- Table extraction logic
- Chunk size and overlap
- Heading-aware splitting
- Metadata enrichment
- Embedding model
- Hybrid lexical/vector weighting
- ANN index parameters
- Filter defaults
- Top-k and reranker thresholds
Document versioning tells you what content existed. It does not tell you how the retriever interpreted and exposed that content.
3. Aggregate answer metrics hide retrieval regressions
Teams often validate changes by running a small answer-level eval set. If answer correctness improves on average, they ship.
This misses an important operational reality: retrieval regressions often show up first as distribution shifts, not as obvious aggregate failures.
Examples:
- Long-form documents improve, but short procedural docs regress.
- Overall hit rate improves, but freshness worsens because effective-date metadata is missing for some content classes.
- Answers remain factually plausible, but citation grounding becomes less precise.
- Restricted documents become retrievable under edge-case filter combinations.
- Query latency spikes at p95 because chunk counts doubled.
If you only look at aggregate answer quality, you can miss the exact class of regressions that matter in production.
4. Indexing changes are often coupled and unexplainable
A common anti-pattern is making multiple changes at once: new parser, new chunking, new metadata, new embeddings, maybe a new reranker. If quality moves, nobody can attribute the effect.
That creates two problems:
- Debugging becomes expensive.
- Teams lose confidence in shipping retrieval changes, so they either stop improving the knowledge layer or make changes recklessly because they lack a disciplined path anyway.
A good release process accepts that some bundled changes are unavoidable, but it preserves enough structure to isolate impacts.
The better approach: versioned retrieval releases with dual indexes and release gates
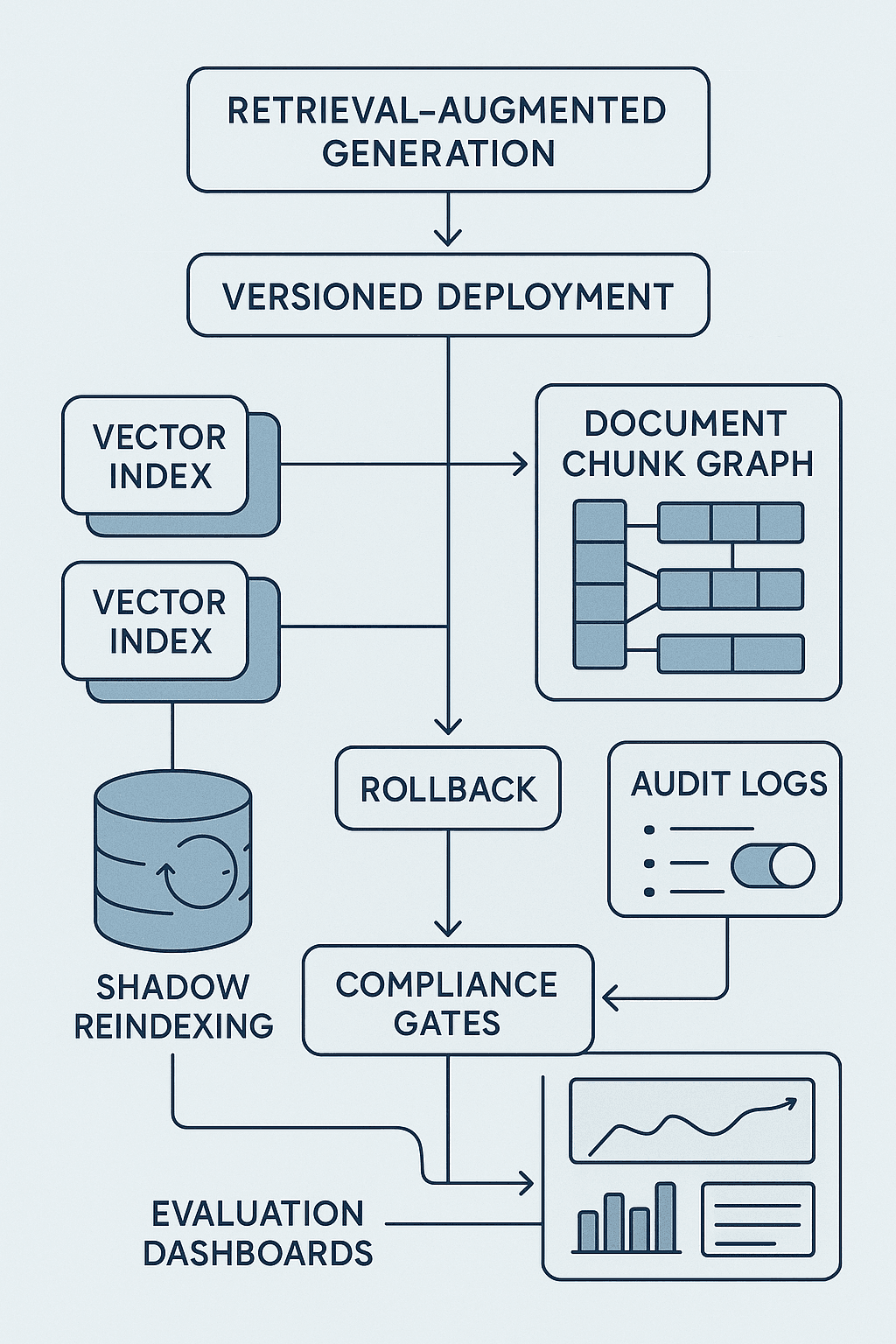
The production pattern I recommend has six core elements:
- Immutable corpus snapshots
- Versioned retrieval specifications
- Dual indexes with alias-based cutover
- Shadow rebuilds and backfill validation
- Retrieval diffing plus answer-level evals
- Rollback and audit built into the serving path
Let’s walk through the architecture.
Reference architecture
At a high level, the system looks like this:
- Source systems: CMS, ticketing, wikis, file stores, databases
- Snapshotter: captures a point-in-time corpus manifest and source blobs
- Normalization pipeline: parsing, OCR, deduplication, canonicalization, ACL attachment
- Chunking/enrichment pipeline: split documents, extract metadata, compute lineage
- Embedding/index build pipeline: compute vectors, lexical features, indexes
- Artifact registry: stores retrieval spec, manifests, schemas, metrics, eval results
- Serving layer: query router points traffic to active release aliases
- Observability/audit layer: logs retrieval release IDs, returned chunks, filters, citations
A releaseable retrieval artifact should have at least these entities:
- Corpus snapshot ID: immutable set of source documents and versions
- Normalized doc manifest: canonical doc IDs, checksums, ACL state
- Chunk manifest: chunk IDs, parent doc IDs, offsets, headings, timestamps
- Schema version: metadata fields, types, semantics
- Embedding manifest: model name, dimensions, quantization settings, batch config
- Index manifest: engine type, ANN parameters, shards, replicas, lexical settings
- Eval report: retrieval metrics, answer metrics, latency/cost, policy checks
- Release decision: approved/rejected, approver, timestamp, notes
This sounds heavy, but much of it is metadata you can generate automatically.
Version the full retrieval contract
When teams say “we changed the index,” they often mean six different things. Make them explicit.
1. Corpus version
Version the exact set of source documents included in the build.
Recommended fields:
source_systemsource_document_idsource_version_idsnapshot_timestampcontent_checksumacl_principal_set_hashdocument_classeffective_datesupersedes_document_id
Why this matters: when a user gets a bad answer, you need to know whether retrieval changed because indexing changed or because source content changed.
2. Normalization version
Parsing and cleanup often drive large quality swings. Version things like:
- OCR engine/version
- PDF table extraction mode
- HTML cleanup rules
- boilerplate removal logic
- language detection
- document deduplication and canonicalization rules
A “corpus unchanged” rebuild can still change behavior dramatically if normalization changes.
3. Chunking version
Chunking is one of the highest-leverage and highest-risk levers in RAG.
Version:
- split strategy: fixed window, sentence-aware, heading-aware, semantic
- target token size and overlap
- table/list preservation rules
- code block handling
- title/heading propagation
- chunk stitching behavior for retrieval-time expansion
Store lineage so every chunk can be traced back to:
- document ID
- source version
- byte or character offsets
- section heading path
- chunker version
That lineage is critical for auditing and diffing.
4. Metadata schema version
This is where many compliance surprises originate. Metadata is not a cosmetic add-on; it is part of retrieval semantics.
Version fields and their definitions:
- access tier n- geography
- business unit
- document status: draft, active, superseded, archived
- effective/expiry date
- product line
- language
- source trust level
Also version derivation logic. A field called status=active means little unless you know how it was computed.
5. Embedding and retrieval stack version
Version:
- embedding model and dimensions
- chunk text template used for embedding
- lexical retrieval config (BM25, sparse vectors, field boosts)
- ANN parameters
- top-k per stage
- reranker model and thresholds
- query rewriting or decomposition logic
The same chunk set can behave very differently with a different embedding prompt template or reranker.
Dual indexes: the safest default for production
If you take one operational idea from this article, make it this: build new retrieval releases in parallel, never in place.
Use dual indexes, or more generally, parallel immutable index generations.
How it works
index_Ais currently serving production traffic.- You build
index_Bfrom a new retrieval spec and corpus snapshot. index_Bis validated offline.- You run shadow or mirrored traffic against
index_Bwithout affecting users. - You compare
index_Aandindex_Busing retrieval diffing and answer evals. - If approved, you cut over by changing an alias or router configuration.
index_Aremains available for rollback until the new release stabilizes.
This pattern is standard in search systems, but many RAG teams skip it because vector infrastructure feels “ML-ish” rather than “release-engineering-ish.” That is a mistake.
Alias-based cutover
Use a stable production alias like:
kb_search_activekb_search_candidate
Your application queries the alias, not the physical index name. Cutover is a metadata update, not a rebuild.
This gives you:
- near-instant rollback
- no partial rebuild exposure
- cleaner metrics attribution by release
- simpler canarying
Storage tradeoff
The obvious downside is temporarily paying for two indexes.
In practice, that cost is often worth it because:
- rebuilds are infrequent relative to query volume
- rollback speed is materially improved
- quality regressions are cheaper to catch before full cutover
- audit requirements may effectively require immutable generations anyway
If storage is expensive, you can optimize with:
- compressed or quantized shadow indexes
- keeping only one previous stable generation hot
- tiered retention for older releases
- hybrid strategy where only changed partitions are duplicated
But do not optimize away your rollback path too early.
Shadow rebuilds and backfills
A safe release process requires more than just building a new index. You need to prove the build is complete and semantically consistent.
Shadow rebuilds
A shadow rebuild means the candidate retrieval release is built in full, end to end, without serving user traffic. It should consume the same source snapshot and the same serving-compatible code path you would use in production.
The purpose is to catch:
- parse failures
- missing metadata
- ACL propagation bugs
- skew in document counts
- unexpectedly large chunk explosions
- embedding failures or truncation
- index capacity or latency issues
Backfill validation
Backfills are where schema migrations often fail. Suppose you add effective_date or policy_status metadata and intend to filter out superseded docs. You must validate not just that the field exists, but that it is populated and correct across historical content.
Useful release checks:
- Percent of chunks with non-null required metadata by document class
- Distribution comparison versus previous release
- Count of docs/chunks excluded by new validation rules
- Count of docs mapped to multiple conflicting statuses
- Freshness logic consistency: active vs superseded populations
- ACL coverage by source system
This is not glamorous work. It is the work that prevents compliance incidents.
Retrieval diffing: compare behavior, not just metrics
One of the most useful techniques in retrieval release management is retrieval diffing.
Instead of asking only, “Did answer correctness improve?”, ask:
- Which chunks were retrieved before vs after?
- Which document classes gained or lost representation?
- Did citations become more or less concentrated in the latest active docs?
- Did restricted or superseded docs appear in candidate results?
- How much rank movement occurred for gold documents?
A practical diffing framework
For a representative query set, store for both baseline and candidate:
- top-k retrieved chunk IDs
- parent document IDs
- scores per stage
- applied filters
- reranker order
- latency breakdown
- answer generated from those contexts
Then compute deltas such as:
- top-k overlap at chunk level
- top-k overlap at document level
- gold doc rank delta
- percentage of queries where the latest valid doc displaced an older one
- percentage of queries that now retrieve superseded content
- metadata distribution delta in retrieved sets
- p50/p95 retrieval and reranking latency delta
- token budget consumed by returned context
Not every retrieval change should preserve overlap. If chunking improves, overlap may drop significantly while answer quality improves. The point of diffing is not to enforce sameness; it is to make changes legible.
Query set design
Your diff set should include more than benchmark questions. Include slices such as:
- exact policy lookups
- ambiguous support questions
- multi-hop product questions
- acronym-heavy internal jargon
- fresh content queries
- access-restricted queries by role
- edge cases involving tables, lists, and long PDFs
- queries tied to previous incidents
If your corpus serves multiple business functions, stratify the set accordingly. Averages can hide painful tail regressions.
Evaluation strategy: release gates that reflect production risk
A retrieval release should pass multiple gates, not one monolithic “eval score.”
Gate 1: Build integrity
Questions to answer:
- Did all expected source systems ingest successfully?
- Are doc and chunk counts within expected bounds?
- Did required metadata pass completeness thresholds?
- Did ACL propagation succeed?
- Did index build complete without hidden fallbacks?
Typical thresholds:
- ≥99.5% of expected docs processed
- 0 unauthorized ACL defaults
- ≥99% completeness for required fields on scoped classes
- chunk count delta within approved range unless explicitly justified
Gate 2: Retrieval quality
Measure retrieval directly, not only final answers.
Useful metrics:
- Recall@k against labeled supporting docs/chunks
- MRR/NDCG for ranked relevance
- Freshness hit rate for time-sensitive corpora
- ACL correctness rate
- citation precision: are returned chunks actually support-bearing?
- duplication rate in top-k
For many enterprise RAG systems, retrieval regressions hurt users before answer metrics fully reveal them.
Gate 3: Answer quality
Then evaluate end-to-end generation.
Useful metrics:
- grounded answer correctness
- citation faithfulness
- abstention quality when support is absent
- policy-specific rubric scores
- task completion on workflow scenarios
Use model graders carefully; calibrate them against human-reviewed sets. For high-risk domains, maintain a gold set with human judgments.
Gate 4: Latency and cost
A retrieval release can improve accuracy while breaking the economics of the system.
Track:
- retrieval p50/p95/p99 latency
- reranker latency
- context tokens passed to generation
- embedding build cost
- steady-state storage cost
- query-time cost per request
Common failure mode: better chunking creates many more candidate chunks, forcing larger top-k, increasing rerank load and prompt token usage. Quality improvement that doubles serving cost may still be acceptable, but it should be an explicit tradeoff.
Gate 5: Compliance and policy checks
This deserves first-class treatment.
Release checks might include:
- zero retrievals of restricted docs under unauthorized principal simulations
- zero citations to superseded policy docs when active versions exist
- regional data segregation rules honored
- retention/deletion requests reflected in candidate index
- source attribution preserved for regulated content
Do not assume these properties hold because the application enforces some top-level rules. Retrieval itself must be tested.
Implementation details that matter in practice
Now let’s get concrete about what teams should build.
1. Use a retrieval spec file
Create a machine-readable spec for each release candidate. YAML or JSON is fine.
Example structure:
yamlrelease_id: kb_2026_06_15_policy_v4 corpus_snapshot: s3://kb-snapshots/2026-06-14T23:00Z/manifest.json normalization: parser_version: pdf-html-parser@3.2.0 ocr_version: ocr-engine@2.1 boilerplate_ruleset: corp-cleanup@5 chunking: strategy: heading_semantic target_tokens: 450 overlap_tokens: 60 preserve_tables: true propagate_heading_path: true metadata_schema: version: policy_meta@4 required_fields: - document_status - effective_date - geography - acl_tags embedding: model: text-embed-large@2026-05 input_template: "{title}\n{heading_path}\n{body}" index: vector_engine: hnsw m: 32 ef_construction: 400 lexical_index: bm25 hybrid_fusion: rrf reranking: model: mini-cross-encoder@1.8 top_k_in: 40 top_k_out: 8 serving: query_rewriter: none default_filters: document_status: active
The point is not the file format. The point is that the release is explicit and reproducible.
2. Give chunks stable lineage-aware IDs
Chunk IDs should encode or map to:
- canonical doc ID
- source version ID
- chunker version
- chunk ordinal or offsets
For example:
doc_481516:ver_19:chunker_2_3_1:off_12000_12880
This makes retrieval diffing, auditing, and citation tracing much easier than opaque random IDs.
3. Log retrieval release IDs on every request
Your serving logs should capture, per request:
- retrieval release ID
- query text or hashed query ID
- user/role/tenant context
- filters applied
- retrieved chunk IDs and ranks
- retrieved parent doc IDs
- stage scores if possible
- generation model version
- final citations
- latency and token usage
This enables post-incident analysis like:
- “Which release produced these bad citations?”
- “Did this issue start exactly at cutover?”
- “Were only EU users affected because geography metadata changed?”
Without release IDs in request logs, root cause analysis becomes inference rather than evidence.
4. Separate canonical documents from derived chunks
Do not let chunks become your only durable unit of storage. Maintain a canonical document store and treat chunks as a derived view.
This helps with:
- rebuilding under new chunking strategies
- re-running metadata extraction
- diffing changes at doc vs chunk granularity
- compliance deletion and source-of-truth audits
It also reduces the temptation to mutate indexes in place because the pipeline naturally rebuilds from canonical inputs.
5. Build query replay infrastructure
Before cutover, replay a representative sample of production queries against both baseline and candidate indexes.
Good replay systems include:
- stratified sampling by intent/domain/tenant
- privacy-safe query handling
- stable snapshots of ACL context
- deterministic configuration for the generation step
- side-by-side capture of retrieval and answer outputs
For internal systems, query replay often finds issues faster than handcrafted eval sets because it reflects actual distribution.
6. Canary at the routing layer
After offline approval, do a small live canary.
Patterns that work:
- 1% traffic by tenant or user cohort
- internal users first
- low-risk intents first
- read-only assistive workflows before autonomous actions
Watch:
- answer acceptance or user edit rate
- fallback/search escalation rate
- citation clickthrough
- support complaints
- latency and error rate
- policy-specific alerts
If something looks off, alias rollback should be immediate.
Model and tool choices: where they affect versioning strategy
The exact stack matters less than the release discipline, but some technology choices change operational tradeoffs.
Vector DB vs search engine with vector support
Dedicated vector DBs
Pros:
- easy embedding-centric workflows
- ANN tuning and managed scaling
- simple APIs for semantic retrieval
Cons:
- metadata filtering and audit tooling may be less mature
- lexical/hybrid search can be less robust depending on vendor
- alias/version management patterns vary widely
Search engines with vector support
Pros:
- mature aliasing, index lifecycle, and audit features
- strong lexical and hybrid retrieval
- operational patterns familiar to search/SRE teams
Cons:
- vector performance or DX may lag specialized systems in some setups
- ANN tuning can be more operationally involved
If your environment has strong compliance, filtering, and search operations requirements, search-engine-style infrastructure often gives you better lifecycle controls. If your workload is mostly semantic retrieval with simpler governance, a vector DB can be fine—provided you implement release metadata and immutable index generations yourself.
Embedding model choices
Switching embedding models is one of the most expensive and disruptive retrieval changes because it usually forces full re-embedding.
Tradeoffs:
- Larger models may improve recall, especially on nuanced internal jargon, but increase build time and cost.
- Smaller models reduce cost and may be enough if reranking is strong.
- Domain-specific embeddings can help but may complicate vendor portability and long-term support.
My advice: treat embedding model changes as major release events. Do not bundle them casually with unrelated parser and schema changes unless you have strong evaluation coverage.
Rerankers
Rerankers can rescue retrieval quality without a full reindex, which makes them attractive operationally. But they also add latency and cost.
A common practical pattern:
- keep embeddings/index relatively stable
- use reranker updates for iterative relevance tuning
- reserve chunking/schema/embedding changes for less frequent retrieval release cycles
That separation reduces the blast radius of each release type.
Cost and latency tradeoffs you should make explicit
Versioning the knowledge layer introduces operational overhead. That is real. The goal is not zero cost; it is controlled risk.
Key tradeoffs:
Dual-index storage vs rollback safety
- Cost: temporary duplicate storage, extra replicas during bake period
- Benefit: instant rollback, better audits, no mixed-state serving
Rich metadata extraction vs ingestion complexity
- Cost: slower pipelines, more failure points, backfill burden
- Benefit: safer filtering, freshness control, compliance enforcement
Smaller chunks vs reranking load
- Cost: more chunks, larger candidate sets, slower query path
- Benefit: better passage-level precision, cleaner citations
Full query replay vs lightweight spot checks
- Cost: infra, storage, reviewer time
- Benefit: catches distribution shifts and tail failures before users do
Frequent incremental updates vs batched releases
- Cost: frequent operational churn and harder attribution
- Benefit: fresher knowledge
A balanced pattern for many enterprise teams is:
- incremental document ingestion into a staging generation
- scheduled release trains for retrieval cutover
- emergency hotfix path only for urgent content or access-control issues
That gives you freshness without constant uncontrolled mutation of the serving artifact.
Rollback strategy: design it before you need it
Rollback is not “we can rebuild the old state if necessary.” In production, rollback means you can restore the last known good retrieval behavior quickly, safely, and with confidence.
A solid rollback plan includes:
- previous release kept queryable and warm
- alias/router switch tested regularly
- release-specific logs and dashboards
- known compatibility rules with the application layer
- incident playbook defining rollback triggers and authority
What should trigger rollback?
Examples:
- retrieval quality metric drops below gate threshold in canary
- unauthorized document exposure detected
- superseded policy citation rate exceeds threshold
- p95 latency exceeds budget materially
- major domain-specific complaint spike after cutover
Compatibility concerns
Sometimes application code depends on metadata or citation formats introduced in the new release. If so, retrieval rollback may break the app. Avoid this by versioning the retrieval API contract too.
For example, the app should tolerate:
- older metadata schemas
- absent optional fields
- multiple citation styles
If application and retrieval changes must ship together, release them with coordinated compatibility windows, not lockstep fragility.
Auditing retrieval changes after the fact
When something goes wrong, you need more than dashboards. You need a forensic trail.
For each answer shown to a user, you should be able to reconstruct:
- which retrieval release served it
- which chunks were retrieved and ranked
- which source documents those chunks came from
- whether any were superseded, restricted, or stale at the time
- what filters and ACL context were applied
- which generation model produced the answer
This is essential for:
- regulated environments
- internal trust with legal/compliance teams
- root cause analysis
- user dispute handling
- postmortems and retraining of eval sets
A good audit design stores both identifiers and enough contextual metadata to inspect the release even if source systems have since changed.
A practical release checklist
Here is a battle-tested checklist I’d use before shipping a retrieval release.
Pre-build
- retrieval spec reviewed
- corpus snapshot sealed
- expected source counts recorded
- migration/backfill plan approved
Build validation
- parse success rates acceptable
- normalized doc count matches expectation
- chunk count delta explained
- required metadata completeness above threshold
- ACL propagation validated
- deleted/retained content handling validated
Offline evaluation
- retrieval metrics pass by slice
- answer metrics pass by slice
- freshness/supersession checks pass
- compliance simulations pass
- latency and cost within budget
- retrieval diffs reviewed for major movement
Shadow/live validation
- query replay completed
- side-by-side inspections completed on sampled failures
- small canary stable
- rollback path tested
Release
- alias cutover executed
- release ID visible in dashboards
- heightened monitoring for agreed period
- previous release retained until signoff
The main takeaway
The knowledge layer in RAG is software, not sediment.
It changes behavior. It can regress silently. It can violate policy in ways the application layer does not catch. And when teams fail to version it properly, they lose the ability to explain, compare, and reverse those changes.
The fix is not exotic research. It is disciplined production engineering:
- immutable corpus snapshots
- explicit retrieval specs
- chunking and schema versioning
- dual indexes instead of in-place rebuilds
- shadow rebuilds and backfill validation
- retrieval diffing, not just answer scoring
- release gates for quality, cost, latency, and compliance
- alias-based rollback
- request-level audit logs keyed by retrieval release
If you adopt that mindset, reindexing stops being a scary one-way operation and becomes a standard release process. Your team can improve chunking, metadata, embeddings, and retrieval logic with confidence because every change is reproducible, reviewable, measurable, and reversible.
That is the difference between a demo-grade RAG stack and a production system your organization can trust.