Failure Modes in Enterprise RAG Permissions: Preventing Access Drift from Indexing to Generation
A team ships an internal assistant for policy, engineering docs, customer escalations, and sales enablement. The prototype looks great in staging. Retrieval quality is solid, the demos land well, and leadership starts talking about rollout timelines.
Then the first production incident happens.
A regional sales manager asks, "What are the renewal risks for Acme?" The assistant answers with a clean summary and three helpful citations. The content is accurate. The problem is that one citation came from an executive-only account review deck stored in SharePoint, and another was pulled from a CRM export that the manager should never have been able to access.
No one wrote a prompt telling the model to leak data. No one intentionally bypassed IAM. The failure came from drift:
- the source system had document ACLs
- the ingestion pipeline flattened them incorrectly
- the vector store retained stale group memberships
- the retriever did broad similarity search first and filtered later
- the reranker saw unauthorized text before filtering
- the response cache returned an answer generated for a more privileged user
- citations exposed exact document titles the user was not allowed to know existed
This is what enterprise RAG permission failures usually look like. Not spectacular break-ins. Mostly ordinary architecture shortcuts that were acceptable in a proof of concept and dangerous in production.
The core lesson is simple: in enterprise RAG, authorization is not a single check. It is a chain of checks that must remain aligned from source system to ingestion to indexing to retrieval to reranking to generation to caching to observability. If any layer drifts, retrieval becomes a side channel.
This article is a production-focused guide to designing document-level and chunk-level authorization into RAG systems so retrieval never leaks data users should not see. I’ll cover common failure modes, why naive approaches fail, and a more robust architecture with evaluation strategy, operational controls, and cost/latency tradeoffs.
The pattern: access drift, not just access control
Most teams think about permissions as a yes/no gate: can user X open document Y? In RAG, the harder problem is whether every intermediate representation of Y remains correctly scoped to X.
That includes:
- raw source documents
- parsed text
- extracted metadata
- chunks
- embeddings
- lexical search indexes
- reranker inputs
- prompt context windows
- citations
- generated summaries
- caches
- traces and logs
The enterprise failure mode is access drift: authorization semantics gradually diverge across layers.
A few representative examples:
1. Document ACLs do not survive chunking
The source document is visible only to Finance Leadership. During chunking, the ingestion job emits 75 chunks but forgets to copy over ACL metadata to each chunk row. Retrieval happens at chunk level, so the vector store returns chunks with effectively public visibility.
2. Group membership snapshots go stale
An employee leaves the M&A diligence team on Friday. HR updates the IdP. SharePoint permissions reflect the change. But the RAG index stores group expansion results materialized during last week’s ingestion. Until the next full sync, the user still retrieves sensitive chunks.
3. Previews and citations leak sensitive existence
Even if the final answer suppresses unauthorized content, a citation block like "Q4 Restructuring Plan - Board Draft" leaks the existence of a restricted document. In some enterprises, knowing that a document exists is itself sensitive.
4. Post-filtering happens too late
The retriever performs ANN search over the entire corpus, returns the top 100 chunks, and only then applies ACL filtering. Even if unauthorized chunks are removed before generation, they may already have influenced reranking, query rewriting, semantic caching, or fallback summarization paths.
5. Shared response caches cross users
A cache key like hash(query_text) is cheap and effective in a consumer app. In enterprise RAG, it can be a data leak. "Summarize open audit issues for Project Atlas" may resolve differently for an internal auditor versus an engineering manager. Reusing the first answer for the second user is a permissions bug.
6. Authorization is checked on retrieve, not on generate
A privileged batch process precomputes summaries of restricted docs for latency reasons. Those summaries are then stored in a general-purpose index or cache with weaker controls than the source. The generated artifacts become a shadow dataset detached from original ACLs.
These are not edge cases. They are what naturally happen when retrieval systems are optimized for relevance first and permission semantics are bolted on afterward.
Why the naive approach fails
The naive enterprise RAG design usually has this shape:
- Sync docs from source systems.
- Chunk and embed them.
- Store vectors and metadata in one index.
- At query time, run retrieval.
- Filter results based on the requesting user.
- Send filtered chunks to the LLM.
It feels reasonable because the visible output is filtered before the model responds. But it fails for several reasons.
Authorization semantics are richer than a metadata field
Real enterprise permissions are not just department=finance.
They often include:
- direct user grants
- nested groups
- deny rules
- inherited permissions from folders/sites/spaces
- external sharing rules
- time-based access
- legal hold or matter-specific restrictions
- row-level security from upstream systems
- environment or region restrictions
If your ingestion pipeline collapses all of this into a simplistic allowlist string, you have already lost fidelity. The RAG system may return results that differ from the source system’s true authorization semantics.
Post-filtering wastes retrieval budget and leaks through side effects
Suppose your ANN retriever returns 50 nearest chunks globally. Then you drop 45 because the user lacks access. Now you have low recall on the authorized subset. The common mitigation is to over-fetch globally, maybe top 500, and then filter. That hurts latency and cost. It also increases the number of unauthorized chunks touched by downstream systems.
Unauthorized chunks can leak indirectly through:
- reranker scores trained or computed over mixed candidate sets
- query expansion informed by restricted corpora
- summaries generated in intermediate steps
- traces captured by observability tools
- debugging snapshots
In other words, post-filtering is not just inefficient. It expands the blast radius.
Group expansion at ingest time goes stale quickly
Teams often materialize ACLs as explicit per-user allowlists because it makes filtering easy. This works at small scale and then becomes operationally brittle.
Problems:
- group memberships change constantly
- nested groups create combinatorial explosion
- per-user ACL expansion inflates index size dramatically
- revocations require urgent propagation
- reindexing becomes the only repair mechanism
The worst case is revocation lag: a user loses access in the source of truth but retains effective access in the RAG stack due to stale ACL materialization.
Chunk-level semantics are harder than document-level semantics
A document may be broadly visible, but only certain sections should be restricted. This appears in:
- contracts with redlined addenda
- board decks with appendix sections
- incident reports with PII-containing segments
- CRM exports merged into larger reports
- wikis where embedded child content inherits different ACLs
If your system only supports document-level authorization, chunking can create overexposure. If you support chunk-level authorization inconsistently, answer generation can stitch together chunks with incompatible visibility rules.
Generation creates derived data that must inherit controls
Generated summaries, extracted entities, Q&A pairs, and semantic caches are all derived artifacts. If they do not inherit source provenance and effective ACLs, they become a permission bypass.
This is especially dangerous in architectures with:
- offline summarization jobs
- knowledge graph extraction
- agent memory stores
- semantic answer caches
- analytics dashboards over retrieval logs
The naive design treats generation as the end of the pipeline. In production, generation creates new data assets that need governance.
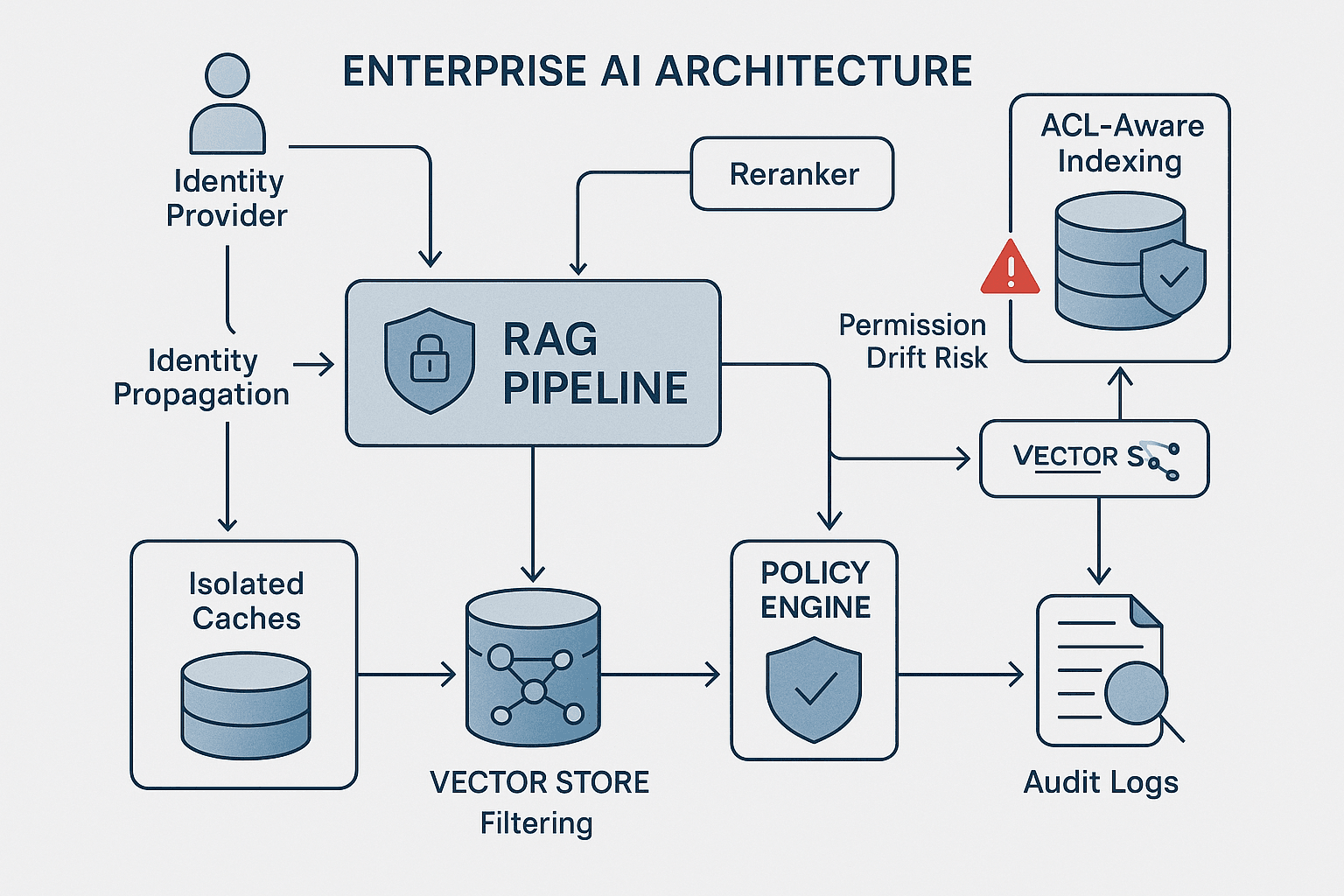
A better approach: ACL-aware RAG as a policy-consistent pipeline
A more robust architecture starts with this design principle:
The system should never retrieve, rank, cache, or generate over content the caller is not authorized to access, and every derived artifact must preserve provenance and effective policy.
That implies a pipeline where identity and policy are first-class concerns, not metadata afterthoughts.
A practical enterprise architecture looks like this:
-
Identity layer
- AuthN via enterprise IdP
- user principal, tenant, region, device/risk context if needed
- on-demand group resolution from source-of-truth or policy engine
-
Policy normalization layer
- connectors ingest source ACL semantics
- canonical policy model represents users, groups, denies, inheritance, and visibility scope
- document/chunk policy fingerprints are computed
-
Ingestion and indexing layer
- parse documents
- chunk content
- attach effective ACL metadata to every chunk
- preserve source provenance
- optionally maintain separate indexes by sensitivity domain or tenant
-
Query-time authorization layer
- resolve caller identity and effective groups fresh enough for SLA
- compile an authorization filter or candidate scope before retrieval
- retrieve only from authorized partitions or with enforceable pre-filters
-
Retrieval and reranking layer
- candidate generation constrained by ACLs
- reranker only sees authorized candidates
- lexical/vector/hybrid retrieval all share the same policy envelope
-
Generation layer
- prompt only includes authorized chunks
- citations filtered for visibility and existence policy
- answer includes provenance
- no hidden scratchpad persistence containing unauthorized text
-
Derived artifact governance
- semantic caches scoped by identity/policy fingerprint
- summaries and extracted facts inherit ACLs and provenance
- downstream stores support revocation and expiry
-
Observability and control plane
- audit every retrieval decision
- measure policy drift
- run permission leakage evals continuously
- support emergency revocation and reindex workflows
That sounds abstract, so let’s get concrete.
Identity propagation: the permission chain starts with the caller
If the assistant loses caller identity at any hop, authorization becomes advisory.
You want a request context that travels end-to-end:
- user ID or service principal
- tenant/org ID
- group claims or token reference
- region/data residency context
- policy version / auth timestamp
- request ID for auditing
A common mistake is having the web app authenticate the user, but the retrieval service call the vector database with a shared backend credential and no user context. In that world, all enforcement depends on application logic behaving perfectly. Better is a pattern where the application still mediates access, but each retrieval request includes a signed authorization envelope or a policy filter compiled from fresh identity context.
For high-stakes systems, separate these concerns:
- authentication service confirms who the user is
- policy decision point (PDP) computes what they may access now
- retrieval service executes only within that scope
This gives you clearer auditability and reduces the chance that retrieval logic invents its own permission semantics.
ACL-aware indexing: preserve effective policy on every retrievable unit
Every retrievable unit must carry enough policy metadata to enforce access correctly. In most enterprise systems, that means chunk-level effective ACLs plus source provenance.
Recommended metadata per chunk:
source_systemsource_document_idsource_versionchunk_idparent_section_idif relevanttenant_idsensitivity_labeleffective_allow_principalsor policy referenceeffective_deny_principalsif applicableacl_inheritance_hashpolicy_fingerprintlast_acl_sync_atcontent_hashderived_fromfor generated artifacts
Two implementation patterns are common.
Pattern A: materialized ACL metadata in the search index
Store effective principals or compact policy attributes directly with chunk metadata.
Pros:
- simple query-time filtering
- fast retrieval
- fewer network hops
Cons:
- index bloat
- stale membership risk
- painful revocations if groups are expanded per user
- limited support for complex deny/inheritance logic
Best used when:
- corpus size is moderate
- ACL model is relatively simple
- revocation SLAs are not ultra-strict
- tenant partitioning already reduces scope
Pattern B: externalized policy references with query-time policy resolution
Store a compact policy ID or document security descriptor on each chunk. At query time, a policy engine resolves whether the caller can access descriptors in the candidate set, or compiles a filter over allowed policy scopes.
Pros:
- more faithful to source semantics
- smaller indexes
- easier revocation without full reindex
- better support for nested groups and denies
Cons:
- more architecture complexity
- can add latency
- requires careful batching and caching of policy decisions
Best used when:
- permissions are complex
- revocation correctness matters a lot
- multiple source systems have heterogeneous ACL semantics
In practice, many mature teams use a hybrid: partition coarsely by tenant/domain/sensitivity, materialize compact policy attributes for fast pre-filtering, and keep an external policy engine for authoritative resolution and revocation handling.
Pre-filtering vs post-filtering: choose your failure mode carefully
This is the key retrieval design choice.
Post-filtering
Flow:
- retrieve top-K globally
- filter by ACL
- rerank/generate on survivors
Advantages:
- simpler to implement
- works even if vector DB filtering is weak
Disadvantages:
- lower recall on authorized corpus
- higher latency from over-fetching
- unauthorized content may influence intermediate stages
- harder to audit and reason about leakage
I would only accept pure post-filtering in low-risk internal prototypes.
Pre-filtering
Flow:
- compute authorized scope first
- retrieve only within that scope
- rerank only authorized candidates
Advantages:
- cleaner security boundary
- better recall within allowed corpus
- lower leakage risk
- easier to align with source semantics
Disadvantages:
- can be slower if filters are expensive
- some ANN engines perform poorly with high-cardinality metadata filters
- query planning is more complex
For enterprise production systems, pre-filtering should be the default goal.
The main question becomes how to make it performant.
Three practical pre-filtering strategies
1. Physical partitioning
Partition indexes by tenant, business unit, sensitivity domain, or repository.
Example:
- separate indexes for HR, Legal, Finance, Engineering
- within each, further partition by tenant or region
Benefits:
- smaller search space
- simpler policy enforcement
- blast-radius reduction
Tradeoff:
- queries spanning multiple domains need federated retrieval
- index management overhead increases
2. Metadata-constrained retrieval
Use vector store filters on policy attributes before or during ANN search.
Benefits:
- flexible
- supports cross-domain search if filters are expressive
Tradeoff:
- performance varies a lot by vendor and index structure
- high-cardinality principal filters can hurt ANN efficiency
3. Two-stage candidate scoping
First retrieve from coarse authorized partitions, then apply a precise policy check on a smaller candidate pool before reranking.
Benefits:
- practical middle ground
- supports external policy engines
Tradeoff:
- needs careful tuning to ensure unauthorized candidates never reach reranker/model
A good production standard is: unauthorized content must not be visible to rerankers or LLMs, even if coarse retrieval briefly touched broader partitions internally. Whether your infrastructure can guarantee that depends on the vendor and your deployment model. If it cannot, do not assume it is safe.
Group membership drift: design for revocation, not just grant
Permission systems fail under revocation pressure.
Grant lag is annoying. Revocation lag is a security incident.
You need an explicit strategy for group membership drift:
Freshness model
Define separate SLAs for:
- document content sync freshness
- document ACL sync freshness
- user/group membership freshness
- revocation propagation time
Most teams define content freshness and forget the other three.
Event-driven updates
Where possible, consume events from:
- IdP group changes
- source repository permission updates
- document moves/renames/inheritance changes
- employee offboarding flows
Use events to trigger targeted reindex or policy invalidation, not just nightly batch syncs.
Policy fingerprints
Assign a fingerprint or version to the effective policy state associated with each chunk/document. Include it in cache keys and audit logs. When ACLs change, invalidate derived artifacts tied to the old fingerprint.
Revocation-first fallbacks
If the policy engine is uncertain or stale, fail closed.
Examples:
- if group expansion service is unavailable, do not widen scope based on stale cache beyond its TTL
- if repository ACL sync is behind threshold, exclude affected content from retrieval until repaired
- if policy descriptors are inconsistent, suppress citations and answer conservatively
This may reduce answer completeness, but it is the correct production tradeoff for sensitive corpora.
Cache isolation: one of the easiest ways to leak data
Caching is where otherwise careful systems quietly break.
You likely have multiple caches:
- embedding cache
- retrieval result cache
- reranker score cache
- prompt assembly cache
- generation/response cache
- semantic answer cache
Each has different security properties.
Safe-ish caches
- document embedding cache keyed by content hash, if embeddings are not exposed and access stays server-side
- parsing/ocr cache keyed by source version
Risky caches
- retrieval results reused across users
- reranker outputs computed over mixed-policy candidate sets
- final answers cached by query text alone
- semantic caches storing answer summaries detached from source ACLs
Minimum standard for cache keys in enterprise RAG:
- normalized query fingerprint
- tenant ID
- user ID or stable permission cohort ID
- policy fingerprint / auth version
- corpus version or index snapshot ID
- model version if output depends on model behavior
In highly sensitive settings, response caches should be per-user, short TTL, or disabled entirely. If you want broader reuse, define permission cohorts carefully and prove with evals that cohorts are authorization-equivalent for the covered corpus.
Also remember that caches need active invalidation on:
- ACL changes
- group membership changes
- document deletion
- legal hold changes
- source document version updates
A cache that does not understand revocation is not an optimization. It is a latent breach.
Citations: provenance helps trust, but also creates leakage paths
Citations are generally good practice in enterprise RAG, but they need policy-aware rendering.
Risks include:
- revealing titles of restricted docs
- exposing filenames, paths, workspace names, or customer account names
- linking to URLs that the app can access but the user cannot
- mixing public-safe snippet text with sensitive metadata
Treat citation rendering as its own authorization step.
Recommended rules:
- only cite sources the user can currently open directly
- suppress or redact titles if existence is sensitive
- bind citations to source version and ACL fingerprint
- never cite generated summaries unless provenance points to underlying authorized sources
- verify that click-through links enforce the same permissions independently
A subtle but important point: if generation synthesizes a sentence from five chunks and one later becomes unauthorized due to revocation, what happens to the stored answer? In many regulated environments, generated answers should not be durable unless they can be invalidated by provenance dependency.
Implementation details: a reference architecture
Here is a concrete reference architecture that works for many enterprises.
Ingestion path
- Connector workers pull docs and ACL metadata from source systems.
- Policy normalizer converts source ACLs into a canonical security descriptor.
- Parser/chunker extracts text and creates chunks.
- Effective policy calculator computes document and chunk-level effective visibility.
- Embedding/indexer writes chunks to lexical and vector indexes with policy metadata or policy references.
- Artifact registry records provenance, content hash, source version, policy fingerprint.
Important implementation notes:
- Keep ACL normalization code per connector explicit and testable. SharePoint, Confluence, Google Drive, S3-backed portals, and custom line-of-business systems all model permissions differently.
- Preserve source IDs and version IDs exactly. You will need them for repair, audit, and revocation.
- If a chunk contains mixed-sensitivity content, either split more aggressively or assign the most restrictive effective ACL.
- Do not let ingestion continue silently if ACL extraction fails. Missing ACLs should default to quarantined/unsearchable, not public.
Query path
- API gateway authenticates user and creates request context.
- Policy service resolves effective groups and policy scope; returns auth token/fingerprint.
- Query planner selects corpora/partitions based on tenant, app scope, sensitivity, and policy.
- Retriever runs hybrid search only inside authorized scope.
- Policy validator re-checks candidate chunks before reranking.
- Reranker scores authorized candidates only.
- Prompt builder assembles context with provenance.
- LLM generates answer with constrained instructions.
- Citation renderer includes only resolvable, currently authorized references.
- Audit logger stores non-sensitive decision traces.
Notice the duplicated policy checks. That is intentional. In security-sensitive systems, redundancy is healthy when boundaries cross services and vendors.
Model and tool comparisons: where permission leakage can still happen
The model itself is rarely the root cause, but tooling choices matter.
Vector stores
Questions to ask vendors or evaluate internally:
- Do metadata filters apply before candidate finalization or after ANN retrieval?
- How do high-cardinality filters impact recall/latency?
- Can indexes be physically partitioned by tenant/domain?
- Is there row-level security support, or is all enforcement app-side?
- Are logs and debug views protected from operators and other tenants?
A vector DB with weak filter semantics can force you into costly over-fetching or unsafe post-filtering. For sensitive workloads, this is not just a performance concern.
Rerankers
Cross-encoders and rerank APIs are excellent for quality, but only if they never see unauthorized candidates.
Questions:
- Is reranking hosted externally? If yes, are you sending sensitive text off-platform?
- Can you self-host for regulated domains?
- What is the token/latency budget for reranking only authorized top-N?
A common compromise is hybrid retrieval with strict pre-filtering, then rerank top 20–50 authorized chunks. This is usually enough to recover quality without broad exposure.
LLMs
The generation model cannot enforce permissions on content it already received. So permission design should minimize dependence on prompt instructions like "do not reveal restricted information." That instruction is useful but not a security control.
Considerations:
- self-hosted or VPC-hosted models for sensitive corpora
- prompt logging disabled or tightly controlled
- structured outputs capturing provenance IDs used in the answer
- lower-context, cheaper models may reduce cost but can require more aggressive retrieval/reranking to maintain quality
Policy engines
External policy engines add complexity but are often worth it when permissions are messy.
What to evaluate:
- latency of policy decisions under load
- support for nested groups and deny rules
- batch decision APIs for candidate sets
- explainability for audit and debugging
- cacheability of decisions and revocation behavior
If your policy layer cannot explain why a chunk was allowed, incident response becomes painful.
Cost and latency tradeoffs
Secure RAG is usually a bit more expensive than naive RAG. The trick is to spend budget where it reduces both risk and wasted computation.
Where secure designs add cost
- ACL extraction and normalization during ingestion
- additional metadata storage per chunk
- policy service lookups at query time
- smaller partitions causing more indexes to manage
- duplicate policy validation before rerank/generation
- cache invalidation complexity
- permission-specific eval infrastructure
Where secure designs save cost
- less over-fetching when pre-filtering is effective
- fewer tokens sent to rerankers/LLMs from unauthorized candidates
- lower incident response and remediation cost
- less need for blanket human review when auditability is strong
Practical latency budget example
For an internal assistant with a 2–4 second target:
- auth + policy resolution: 50–150 ms
- partition selection and retrieval: 100–400 ms
- policy revalidation: 20–80 ms
- rerank top 20–30 authorized chunks: 100–300 ms
- LLM generation: 700–2000 ms
- citation rendering + logging: 20–100 ms
The budget pressure tends to push teams toward caching. That is fine, but caches must be policy-scoped and revocation-aware.
In many environments, the best latency win is coarse partitioning by tenant/domain so retrieval starts in the right place rather than relying on giant global indexes with expensive principal filters.
Evals: test for permission leakage explicitly
Most RAG evals focus on relevance, faithfulness, and answer quality. Enterprise systems need a parallel security eval suite for permission leakage.
This should be treated as a release gate, not a nice-to-have.
Core permission eval categories
1. Positive authorization tests
Given user U with access to documents A and B, verify the system can retrieve and cite them correctly.
Why it matters:
- overly conservative filtering can make the system useless
- secure and useful is the actual target
2. Negative authorization tests
Given user U without access to document C, verify:
- C is not retrieved
- chunks from C are not reranked
- generation contains no facts unique to C
- citations do not reveal C’s title/path/existence
- caches do not serve content derived from C
3. Revocation tests
Simulate user losing access or document ACL tightening. Measure:
- time until retrieval stops returning affected chunks
- cache invalidation completeness
- whether old generated summaries remain visible
Track this as a hard metric: revocation propagation latency.
4. Group drift tests
Change nested group membership across systems and validate end-to-end behavior with realistic sync delays.
5. Mixed-sensitivity document tests
Ensure chunking and section-level ACL logic handle embedded restricted sections correctly.
6. Side-channel tests
Probe for leakage through:
- answer wording hints
- citations and filenames
- empty-result explanations
- latency differences
- ranking artifacts
- conversation memory
Building a permission eval dataset
Create a corpus with synthetic but realistic ACL complexity:
- overlapping departments
- nested groups
- deny exceptions
- documents moved between folders
- user offboarding scenarios
- tenant-segregated content
- documents with restricted appendices
Then generate user personas with known effective access maps. For each query, define:
- authorized source set
- unauthorized source set
- expected answerability
- allowed citation set
- forbidden entities/phrases/titles
This lets you score not just relevance but leakage rate.
Metrics that matter
Add these to your dashboard:
- unauthorized retrieval rate
- unauthorized rerank exposure rate
- unauthorized citation rate
- generated leakage rate
- revocation propagation latency p50/p95/p99
- ACL sync lag by source system
- stale policy fingerprint hit rate
- cross-user cache contamination rate
If you only measure answer quality, you will miss the thing that gets you paged.
Operational controls: the unglamorous work that keeps the system safe
Security in enterprise RAG is mostly operations.
1. Quarantine on ACL extraction failure
If a connector cannot determine effective permissions for a document, that content should not enter retrievable indexes. Put it in quarantine, alert, and repair.
2. Emergency revocation playbook
Have a documented way to:
- invalidate policy caches
- invalidate retrieval/response caches
- deindex or suppress affected documents/chunks
- replay ACL sync for a source or tenant
- audit which users may have seen affected content
3. Drift monitoring
Continuously compare:
- source system ACLs
- normalized policy descriptors
- indexed policy fingerprints
- query-time effective decisions
Any mismatch should be observable.
4. Least-privilege service design
Connectors, indexers, and retrieval services should not all run with broad superuser access if avoidable. Segment duties and credentials.
5. Logging discipline
Audit logs are essential, but logs themselves must not become data exfiltration paths. Avoid storing raw restricted chunks in traces. Prefer IDs, hashes, policy fingerprints, and minimal excerpts only when permitted.
6. Derived artifact lifecycle management
Summaries, extracted entities, and caches need TTLs, provenance, and revocation hooks. If you cannot invalidate a derived artifact when source permissions change, it should not be durable.
7. Human review and red teaming
Before each major release, run targeted red-team scenarios against permission boundaries, not just jailbreak prompts. The adversary here is often a normal employee with partial access and curiosity.
Common design decisions and my recommendations
Should you do doc-level or chunk-level ACLs?
If source systems are doc-level and documents are homogeneous, doc-level may be enough initially. But if chunking crosses sensitivity boundaries, chunk-level ACLs are safer. In mixed-content corpora, default to chunk-level effective policy with conservative splitting.
Should group memberships be expanded in the index?
Avoid full per-user expansion unless the corpus is small and revocation risk is low. Prefer group or policy descriptor references plus query-time resolution.
Can post-filtering ever be acceptable?
Only for low-risk prototypes or as a temporary backstop behind strong partitioning, never as the primary security mechanism for sensitive enterprise content.
Should you cache answers?
Yes, cautiously. Use policy-scoped keys, short TTLs, provenance, and invalidation on ACL/content changes. In high-sensitivity domains, keep caches per-user or disable answer caching.
Are citations always good?
Usually, but only if they are separately authorized and do not leak sensitive existence metadata.
The mental model to keep your team honest
Do not think of enterprise RAG permissions as "adding ACL filters to search." Think of it as maintaining policy consistency across representations.
The source document, the chunk, the embedding, the retrieval candidate, the reranked list, the prompt context, the citation, the cached answer, and the audit trail are all different representations of the same protected information. If policy is lost or weakened in any transformation, the system drifts.
The teams that avoid incidents do three things consistently:
- they propagate identity and policy end-to-end
- they enforce authorization before expensive semantic operations
- they evaluate and operate for revocation, drift, and derived-data governance
Takeaways
A production RAG system is not secure because the final prompt says "only answer from allowed documents." It is secure when unauthorized content never becomes part of the retrieval, reranking, caching, or generation path in the first place.
If you are building enterprise RAG, the practical checklist is:
- propagate caller identity through every service hop
- normalize source ACLs into a canonical, testable policy model
- attach effective policy to every retrievable unit, ideally chunk-level where needed
- favor pre-filtered retrieval using partitions and enforceable metadata constraints
- ensure rerankers and LLMs never see unauthorized text
- design caches with policy-aware keys and revocation hooks
- treat citations as a separate authorization surface
- run explicit permission leakage evals, including revocation and drift scenarios
- quarantine content when ACL extraction fails
- maintain provenance and policy fingerprints for every derived artifact
Prototype RAG systems fail safely only by luck. Production systems need deliberate architecture.
In enterprise environments, relevance bugs are annoying. Permission drift is existential. Build accordingly.