Building a Cost-and-Latency Budget for Production RAG Systems
A team ships a promising RAG assistant for customer support. Early demos look great: the system retrieves a handful of relevant documents, sends them to a strong model, and answers with citations. Then traffic grows.
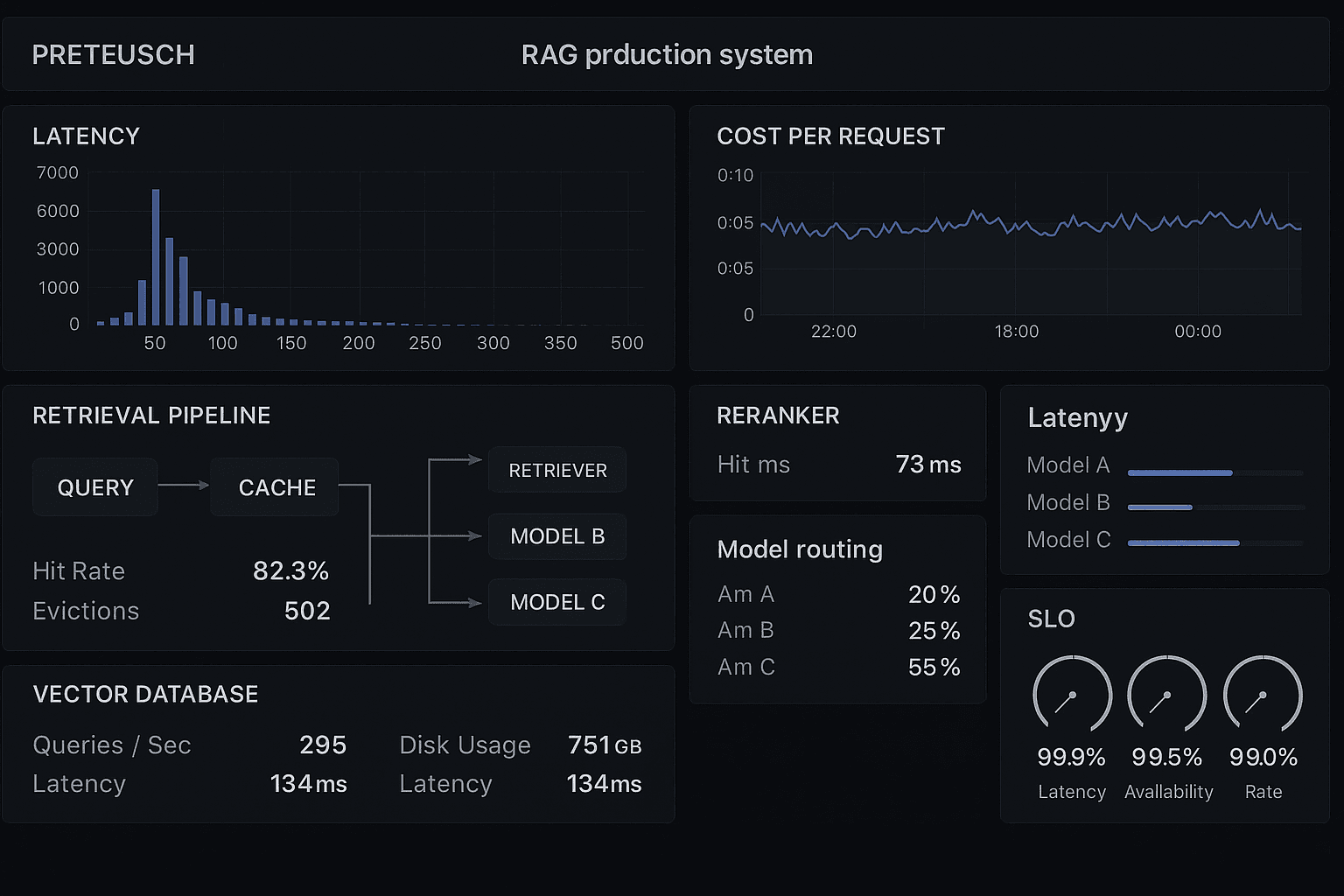
At a few hundred requests per hour, the cracks show. P95 latency climbs above eight seconds. Token spend is much higher than forecast. The vector database bill is surprisingly material because every query fans out across multiple indexes and metadata filters. A cross-encoder reranker that looked harmless in staging becomes the dominant latency source in production. Engineers add caching, but it barely moves the needle because requests are too semantically diverse. Product asks for better answer quality, but the only obvious knob is “retrieve more documents and use a bigger model,” which makes cost and latency even worse.
This is where many RAG systems stop being an ML problem and become a systems engineering problem.
The teams that get production RAG under control are usually the ones that stop tuning components in isolation and start designing to explicit budgets: a latency budget, a cost budget, and a quality floor. Instead of asking “what is the best retriever?” or “which model is smartest?”, they ask:
- How many milliseconds can retrieval consume at P95?
- How many tokens can we spend per request at steady state?
- Which requests deserve expensive reranking or larger models?
- Which steps can run in parallel?
- Where do we accept graceful degradation instead of timeout?
- How do we prove optimization did not silently reduce answer quality?
That budget mindset is what turns a fragile demo into an operable production system.
The pattern: RAG pipelines fail when every stage optimizes for local quality
A typical production RAG stack has more moving parts than teams initially expect:
- Query normalization or rewriting
- Embedding generation
- Vector retrieval, often from multiple corpora
- Lexical retrieval or hybrid fusion
- Metadata filtering and ACL checks
- Reranking
- Context packing and deduplication
- LLM answer generation
- Tool calls for citations, structured data, or live lookups
- Logging, tracing, safety checks, and post-processing
Each stage can improve quality. Each stage also adds latency variance and direct or indirect cost.
The failure pattern is predictable:
- Retrieval fan-out grows because recall problems are easier to “solve” by retrieving more.
- Reranking depth grows because irrelevant chunks leak into context.
- Context size grows because teams fear dropping useful evidence.
- Model size grows because poor retrieval and packing force the generator to do more reasoning over noisy context.
- Tool calls grow because the system lacks confidence thresholds or fallback rules.
The result is a pipeline where every stage compensates for upstream imprecision by consuming more time and money downstream.
The naive mental model is linear: “If each step is good, the system will be good.” The production reality is budget-constrained and multiplicative: more fan-out increases rerank load; more rerank depth increases packing complexity; larger contexts increase generation latency and token cost; slower generation raises concurrency pressure and queue times; queue times push tail latency beyond your SLO.
If you do not set explicit per-stage budgets, the system will consume whatever resources the components can get away with.
Why the naive approach fails
There are four common reasons teams struggle to control cost and latency in RAG.
1. They optimize average latency instead of tail latency
Users do not experience average latency; they experience P95 and timeouts. RAG pipelines are especially tail-heavy because they chain network hops, external services, and variable-sized prompts.
A simple example:
- Embedding call: P50 80 ms, P95 180 ms
- Vector search: P50 120 ms, P95 350 ms
- Reranker: P50 180 ms, P95 700 ms
- Generation: P50 900 ms, P95 2,800 ms
Averages look fine. Tail composition does not. If these calls are serial, your P95 quickly blows through a three-second target. Even worse, generation latency often expands with prompt size, so retrieval variance and prompt variance reinforce each other.
Designing a budget means assigning a P95 envelope to each stage and treating overages as architecture issues, not mere tuning annoyances.
2. They track LLM token cost but ignore system cost
Teams often know their prompt and completion token spend down to the cent. They much less often track:
- Embedding tokens and embedding request volume
- Vector database read units or query charges
- Reranker inference cost, especially if GPU-hosted
- Tool-call latency and third-party API charges
- Cache miss penalties
- Queueing costs under concurrency
- Hidden cost of retries and fallbacks
In many production RAG systems, the generator is still the largest line item, but not always by as much as people assume. A retrieval strategy that fans out across five indexes, reranks 100 candidates, and fetches full documents for packing can create a nontrivial per-request serving bill before generation even starts.
If you only optimize token cost, you may shift expense into infrastructure and increase latency while thinking you improved unit economics.
3. They treat all queries as equally valuable
Not every question deserves the same pipeline.
A navigational query like “What is our refund policy for annual plans?” does not need multi-index retrieval, deep reranking, and the largest reasoning model. A complex policy synthesis question across product, legal, and account history might.
Flat pipelines are easy to ship but expensive to run. Model routing, retrieval routing, and policy-based escalation are not premature optimization in production RAG; they are core design tools.
4. They optimize without a quality safety net
The easiest way to cut cost and latency is to retrieve less context and call a smaller model. Sometimes that works. Sometimes you quietly reduce citation grounding, increase hallucination, or fail on long-tail queries. Teams often discover this only after complaints arrive.
Every optimization needs an evaluation harness that measures task success, answer faithfulness, citation accuracy, and failure mode frequency. Otherwise, “efficiency” becomes undetected quality regression.
A better approach: design around budgets, classes of service, and graceful degradation
The better pattern is to build RAG as a budgeted pipeline with three explicit controls:
- A cost budget: target cost per request and per successful task.
- A latency budget: stage-level and end-to-end SLOs, especially P95.
- A quality floor: minimum acceptable performance on offline and online evals.
Then route requests through classes of service.
For example:
- Class A: fast path for common, well-covered queries
- Tight latency budget
- Modest retrieval fan-out
- Small or mid-sized generator
- Aggressive caching
- Class B: standard path for ambiguous or moderately difficult questions
- Hybrid retrieval
- Deeper reranking
- Larger context budget
- Class C: expensive path for high-value or high-complexity queries
- Multi-source retrieval
- Strong reranker
- Larger model or tool-augmented response
- Higher allowed latency and cost
This is not just request classification for elegance. It is how you preserve budget for the queries that need it instead of overserving everything.
A good production architecture usually looks like this:
Reference architecture for a budgeted production RAG system
1. Query intake and early classification
At request start, compute cheap signals:
- Query length and structure
- Presence of entities, dates, product names, IDs
- User segment or plan tier
- Corpus/domain target if known
- Historical cache hit likelihood
- Estimated complexity from a small classifier model or heuristic
- Required response mode: extractive answer, synthesis, recommendation, workflow action
Use these signals to route the request into a class of service.
A lightweight router can decide:
- Whether to use semantic retrieval only or hybrid retrieval
- Which corpus/indexes to search
- Whether reranking is needed
- Context budget ceiling
- Which generator model to use first
- Whether to enable live tools
The router should be cheap. If the router itself becomes expensive, you have moved the problem, not solved it.
2. Retrieval with controlled fan-out
Retrieval fan-out is one of the biggest hidden levers in RAG cost and latency.
Fan-out exists at multiple levels:
- Number of corpora or indexes queried
- Number of retrieval methods used, such as vector + BM25
- Top-k candidates retrieved from each source
- Number of metadata-filter variants attempted
Naively increasing top-k usually improves recall at first and then starts adding mostly noise. That noise has downstream cost.
A practical pattern:
- Start with domain routing so most requests hit one primary corpus, not all corpora.
- Use modest top-k per retriever, such as 10–30, not 100 by default.
- Fuse retrievers with reciprocal rank fusion or weighted merge.
- Apply cheap chunk-level deduplication before reranking.
- Cap total candidates entering reranking.
A typical budgeted configuration might be:
- Vector retriever top-k: 12
- BM25 retriever top-k: 8
- Fused unique candidates: capped at 15
- Reranked candidates: top 15 in, top 5 out
- Packed chunks: 3–6 depending on token budget
The exact values depend on corpus quality and chunking strategy, but the principle is durable: keep recall high enough, then aggressively control downstream load.
3. Reranking only where it pays for itself
Reranking is valuable because first-pass retrieval is often optimized for recall, not precision. But reranking can become the latency sink.
Common reranker options:
- Cross-encoder rerankers: strong relevance, higher latency and compute cost
- LLM-based reranking: potentially strong, usually too expensive for broad usage
- Lightweight learned rankers or heuristics: faster, weaker, often good enough for common cases
A battle-tested approach is conditional reranking:
- Skip reranking when the top retrieval scores are sharply separated and the query is simple.
- Use a lightweight reranker on the fast path.
- Escalate to a stronger cross-encoder only when ambiguity is high or quality impact is material.
Define an explicit rerank budget:
- Max input candidates
- Max time allowed
- Timeout fallback behavior
If reranking exceeds budget, the pipeline should continue with first-pass retrieval rather than failing the request. Graceful degradation is often better than timeout.
4. Context packing as an optimization problem, not append-only accumulation
Many teams treat context packing as “take top chunks until token limit.” That is expensive and often reduces answer quality.
Why? Because redundant chunks, partial chunks, and near-duplicate passages waste context space and increase generation latency without increasing evidence coverage.
Better packing usually includes:
- Near-duplicate removal
- Parent-document grouping
- Section-aware chunk merging
- Diversity constraints across sources or subtopics
- Hard token budget per request class
- Reserved budget for instructions, user question, and citations
A useful mental model is coverage over redundancy. You want the smallest set of chunks that covers the likely evidence required to answer.
For example, if your context budget for the standard path is 3,000 input tokens, do not let retrieval consume 2,900 of them. Reserve room explicitly:
- System and task instructions: 400
- Conversation state: 300
- User query and reformulations: 150
- Retrieved context: 1,800
- Citation wrapper/formatting overhead: 350
These numbers vary, but fixed sub-budgets force discipline.
5. Model routing instead of one-model-for-all
Generator model choice is another major budget lever. In production, “always use the best model” is usually another way of saying “we do not have routing yet.”
A practical routing strategy:
- Small model for extractive or templated answers when retrieval confidence is high
- Mid-sized model for standard synthesis over moderate context
- Large model only for complex reasoning, low-confidence retrieval, or premium/high-value tasks
Routing inputs can include:
- Query complexity
- Retrieved evidence confidence n- Need for structured output
- User tier or workflow criticality
- Whether prior attempt failed validation
The best routing policies are measurable. For each route, track:
- Cost per request
- Latency distribution
- Task success rate
- Escalation rate
- Net savings versus baseline
If the small model causes frequent retries or escalations, its apparent savings may disappear.
6. Caching layers that map to the actual workload
Caching in RAG is not one thing. Different layers solve different cost problems.
Useful cache layers include:
- Embedding cache: avoids re-embedding repeated queries or documents
- Retrieval cache: stores search results for exact or normalized queries
- Semantic answer cache: returns prior answers for near-duplicate questions when safe
- Chunk/document fetch cache: avoids repeated document hydration
- Prompt prefix cache: useful when the serving stack supports prompt caching or reuse
- Tool response cache: for stable external data sources
A common mistake is to jump straight to semantic answer caching and ignore easier wins like embedding and document hydration caches.
Cache design should answer:
- What is being cached?
- What is the invalidation policy?
- What is the staleness tolerance?
- Is the cache safe across users, tenants, and ACL boundaries?
- What is the hit rate by class of service?
In many enterprise RAG systems, retrieval and hydration caches produce more predictable wins than answer caches because user phrasing varies but corpus hotspots repeat.
7. Async orchestration and partial parallelism
If your pipeline is fully serial, you are paying a latency tax you probably do not need to pay.
Look for independent or partially independent work that can run in parallel:
- Query classification alongside query normalization
- Vector and lexical retrieval in parallel
- Retrieval from multiple corpora in parallel when routing permits
- Document hydration for top candidates while reranking is in progress
- Safety or formatting checks after generation starts streaming
The caution: parallelism can increase infrastructure cost and burst load even while reducing latency. This is why budgeting must include throughput and concurrency, not just per-request time.
Async orchestration also means using deadlines and cancellation correctly. If a slow branch is no longer needed because another branch produced enough evidence, cancel it. Otherwise, you are spending money for results you will throw away.
8. Fallback policies instead of brittle all-or-nothing behavior
Production RAG systems need explicit fallback policy trees.
Examples:
- If hybrid retrieval fails, fall back to vector-only.
- If reranker times out, use fused retrieval ranking.
- If large model quota is exhausted, route to mid-sized model with stricter answer style.
- If context budget is exceeded, compress or reduce evidence set rather than fail.
- If grounding confidence is low, answer conservatively or abstain.
The right fallback is task-dependent. For support and policy use cases, conservative abstention with citations is often better than speculative synthesis. For internal knowledge work, users may prefer a best-effort answer with confidence cues.
The key is that fallback policy is part of the budget design. If every component timeout becomes a user-visible failure, your system is not production-ready.
How to build the actual budget
A budget needs math, not just principles.
Start with business and user constraints:
- P95 latency target: for example, 3.5 seconds
- Unit cost target: for example, $0.015 per request blended
- Minimum quality floor: for example, no more than 2% drop in grounded-answer accuracy from baseline
- Throughput target: for example, 20 requests/sec sustained with burst to 50
Then allocate stage budgets.
Here is a representative end-to-end budget for a standard path:
- Query classification/normalization: 100 ms
- Embedding: 120 ms
- Retrieval: 250 ms
- Reranking: 250 ms
- Context packing/hydration: 180 ms
- Generation first token: 600 ms
- Generation completion/streaming tail: 1,500 ms
- Slack/retries/orchestration overhead: 500 ms
Total P95 envelope: 3,500 ms
Now add direct cost budgets per request:
- Embedding: $0.0002
- Vector/lexical retrieval infra: $0.0010
- Reranker inference: $0.0015
- Document hydration/cache misses: $0.0005
- Generator prompt tokens: $0.0050
- Generator completion tokens: $0.0045
- Tool/API calls: $0.0015
- Observability/overhead allocation: $0.0008
Total target: $0.0150
This is not about perfect accounting precision. It is about making tradeoffs visible. If product asks to double retrieval depth, you can estimate its impact on reranking cost, context size, and generation latency before shipping it.
Instrumentation: measure tokens, vectors, tools, and queueing
You cannot manage a RAG budget without request-level attribution.
At minimum, log the following per request:
Identity and routing
- Request ID
- Tenant/user segment
- Query class of service
- Chosen retrievers, reranker, generator, and tools
- Fallbacks triggered
Latency
- End-to-end latency
- Per-stage latency
- Queue wait time
- Network vs model inference time where available
- Time to first token and time to last token
Cost proxies and direct costs
- Prompt and completion tokens
- Embedding tokens
- Number of vector searches
- Vector DB read units/query charges if exposed
- Number of reranked candidates
- Reranker inference time and compute tier
- Tool-call counts, durations, and direct API charges
- Cache hits/misses at every layer
Quality and behavior signals
- Retrieval score stats
- Grounding/confidence score
- Number of citations used
- Abstention flag
- User feedback if available
- Validation or policy check outcomes
Store these in a way that supports slicing by:
- Query type
- Corpus/domain
- Model route
- Customer tier
- Prompt version
- Retrieval configuration version
Without versioned configs in telemetry, you will not know which optimization caused a regression.
Evaluation strategy: optimize safely, not blindly
Every budget optimization should run through offline and online evaluation.
Offline evaluation set design
Build a labeled set that reflects production reality, not just easy golden-path questions. Include:
- Frequent head queries
- Ambiguous queries
- Long-tail domain questions
- Multi-hop synthesis tasks
- Cases with sparse or conflicting evidence
- ACL-sensitive cases if relevant
- “Should abstain” cases
For each example, capture:
- Expected answer or rubric
- Required supporting documents/chunks if known
- Whether a grounded answer is possible
- Severity of failure if answered incorrectly
Metrics that matter for RAG budgets
Track at least these metrics before and after optimization:
- Retrieval recall@k against known evidence
- Reranker NDCG or precision at packed depth
- Grounded answer correctness
- Citation accuracy
- Hallucination/unsupported claim rate
- Abstention appropriateness
- End-to-end task success
- Cost per request
- P50/P95 latency
One important habit: separate retrieval quality from generation quality. If answer quality drops, you need to know whether retrieval lost evidence, packing removed useful context, or model routing picked too weak a generator.
Online evaluation and guardrails
In production, use:
- Shadow experiments for alternative retrieval/rerank configs
- A/B tests by request class
- Canary rollout by tenant or traffic slice
- Alerts on quality proxies like citation drop rate, fallback spike rate, or unexplained abstention increase
Do not ship latency and cost optimizations globally without a rollback path.
Concrete tradeoffs by design lever
Let’s make the knobs more explicit.
Retrieval fan-out
Increase fan-out
- Pros: better recall, more robust on ambiguous queries
- Cons: more vector cost, more rerank load, more packing work, more prompt bloat risk
When to do it
- Sparse corpora
- High ambiguity
- Cross-domain questions
When not to
- Well-routed single-domain queries
- Highly repetitive FAQ-style traffic
Reranking depth
Increase depth
- Pros: cleaner top context, often better answer quality
- Cons: latency and compute rise quickly
When to do it
- Retrieval returns many plausible chunks
- Chunk quality is noisy
- Answer quality strongly depends on ranking precision
When not to
- Queries with obvious exact-match results
- Corpora with already strong retrieval precision
Context packing budget
Increase context tokens
- Pros: potentially more evidence coverage
- Cons: token cost rises, generation slows, model may attend poorly to noisy or redundant context
When to do it
- Genuine multi-document synthesis
- Large policy comparisons
- Long-document question answering with dispersed evidence
When not to
- Extractive Q&A
- FAQ-style questions with one or two supporting chunks
Model routing
Use larger model more often
- Pros: stronger reasoning and robustness
- Cons: higher cost, slower, may hide retrieval weaknesses
When to do it
- High-stakes requests
- Complex synthesis or structured reasoning
- Low-confidence retrieval cases
When not to
- Simple grounded extraction
- High-volume low-value requests
Caching
Expand caching
- Pros: substantial cost and latency wins on repetitive workloads
- Cons: invalidation complexity, staleness risk, tenant isolation concerns
When to do it
- Stable corpora
- Hot queries/documents
- Expensive hydration or tool calls
When not to
- Highly dynamic or personalized data without strong invalidation controls
Implementation details that matter more than people think
Chunking strategy sets your downstream budget envelope
Poor chunking forces expensive retrieval and reranking. If chunks are too small, you retrieve many fragments and increase top-k needs. If chunks are too large, vector precision drops and prompt cost rises.
In practice, chunking should be evaluated together with retrieval depth and packing policy. Parent-child retrieval or section-aware chunking often improves evidence coverage without exploding context.
Metadata filtering is quality and cost control
Good metadata can cut fan-out dramatically:
- Product area
- Document type
- Region/jurisdiction
- Version/effective date
- Access control tags
A well-designed filter strategy reduces irrelevant retrieval before reranking, which is much cheaper than fixing it later.
Timeouts need to be stage-specific
A single global timeout is not enough. Give each stage a budget and define what happens on timeout.
For example:
- Retrieval timeout: return best available source
- Reranker timeout: skip rerank
- Tool timeout: continue with static corpus answer if safe
- Generation timeout: return partial answer only if policy allows, otherwise fail gracefully
This avoids one slow dependency consuming the entire request envelope.
Concurrency controls protect tail latency
Even efficient per-request pipelines fail under load if concurrency is unmanaged. Generation calls, rerank GPUs, and vector DB hot partitions can all create queueing.
Track and control:
- Max in-flight requests per model tier
- Separate pools for premium/critical routes
- Backpressure thresholds
- Shed-load policy for low-priority requests
Tail latency often improves more from queueing control than from micro-optimizing prompt templates.
Prompt design affects cost more than most teams admit
Verbose system instructions, repeated policy text, and overly chatty citation scaffolding all add up. Prompt compression and reusable prompt prefixes are legitimate optimization work.
The test is simple: if removing 300 prompt tokens has no measurable quality impact, those 300 tokens were a tax.
A practical rollout plan
If your current RAG system feels too expensive and too slow, do not try to optimize everything at once. Use this order.
Phase 1: Establish visibility
- Add per-stage tracing and cost attribution
- Measure token, vector, rerank, tool, and cache metrics
- Define P50/P95 and unit-cost baselines by query type
- Create a representative offline eval set
Phase 2: Attack obvious waste
- Cap retrieval fan-out
- Deduplicate chunks before reranking
- Enforce context token ceilings
- Add embedding and hydration caches
- Remove prompt verbosity that does not help quality
These changes often produce meaningful savings with low quality risk.
Phase 3: Add routing and graceful degradation
- Introduce classes of service
- Route simple requests to cheaper models and shallower retrieval
- Add rerank skip logic
- Implement timeout fallbacks instead of hard failures
This is where unit economics usually improve materially.
Phase 4: Optimize for throughput and tails
- Parallelize independent branches
- Add cancellation and deadlines
- Tune concurrency pools
- Separate premium/high-priority traffic
- Revisit hot indexes and cache locality
This is where you convert a merely cheaper system into a reliable one.
Phase 5: Close the loop with evals
- Run regression tests on every retrieval, routing, and prompt change
- Compare quality, cost, and latency together
- Promote only configurations that stay above the quality floor while improving economics
Model and tool comparison framework
Teams often ask for a fixed recommendation like “which reranker?” or “which model tier?” In practice, choose by role and budget fit.
Retriever choices
- Dense/vector retrieval: strong semantic recall, standard default, sensitive to chunking and embedding quality
- BM25/lexical: cheap and excellent for exact terms, IDs, error codes, product names
- Hybrid retrieval: usually best production default when corpora contain both semantic and exact-match needs
Reranker choices
- Heuristic/lightweight rankers: fastest, useful for common-case pruning
- Cross-encoders: strongest precision for many tasks, expensive at depth
- LLM rerankers: usually reserve for narrow high-value workflows or offline labeling
Generator choices
- Small models: low cost, fast, good for extraction, templating, simple grounded answers
- Mid-tier models: strong default for many enterprise RAG tasks
- Large reasoning models: use sparingly where complexity or stakes justify them
The right comparison is not benchmark score in isolation. It is:
- Quality on your eval set
- Cost at your average prompt size
- Latency at your concurrency level
- Failure behavior under noisy retrieval
- Routing compatibility with the rest of the stack
Takeaways
Production RAG systems do not become efficient because one component gets better. They become efficient because the team starts treating the system like a budgeted pipeline with explicit tradeoffs.
The important shifts are straightforward:
- Set cost and latency budgets before tuning components.
- Design for P95, not just averages.
- Use classes of service instead of one expensive path for every request.
- Control retrieval fan-out and reranking depth aggressively.
- Treat context packing as a first-class optimization problem.
- Route models based on query complexity and evidence confidence.
- Add cache layers where your workload actually repeats.
- Orchestrate asynchronously, cancel wasted work, and define fallbacks.
- Instrument everything at request level, including vector and tool costs.
- Protect quality with retrieval and end-to-end evals on every optimization.
The honest truth is that production RAG is a balancing act. If you chase quality without budgets, cost and latency will drift until the system is hard to operate. If you chase efficiency without evals, quality will erode silently. The teams that win are the ones that make tradeoffs explicit, measurable, and reversible.
That is the real job: not building a RAG demo that works once, but building a retrieval-generation service that can meet an SLO, survive load, and make economic sense every day in production.